La logique du builder IA : pourquoi la méta-question change tout

J’ai un aveu. Pendant six mois, à chaque fois qu’un agent IA me sortait une connerie, mon premier réflexe c’était : “il est nul, ce modèle”.
Je ragequit. Je relançais. Je changeais de prompt. Parfois je changeais carrément de modèle. Et je recommençais le lendemain avec exactement les mêmes erreurs.
Pendant ce temps, mon copain dev qui bossait sur le même type de projets devenait deux fois plus rapide que moi. Pas parce qu’il avait un meilleur modèle. Parce qu’il avait une meilleure logique face à l’erreur.
Et c’est cette logique-là, que j’ai mis trop longtemps à piger, qui sépare les builders qui galèrent éternellement des builders dont les agents deviennent meilleurs chaque semaine.
Acte 1, le piège de la première impression
Le scénario type, tu le connais.
Tu demandes à Claude (ou n’importe quel agent) d’implémenter une feature. Il génère 200 lignes. Tu lances. Ça crash. Ou pire : ça compile, ça tourne, mais c’est de la merde architecturale, un repository importé directement dans un widget, de la logique métier dans un build(), un fichier de 400 lignes avec trois classes dedans.
Et là, deux mondes se séparent.
Le premier monde, celui dans lequel j’ai vécu six mois, c’est le monde où tu traites le symptôme. Tu copies-colles l’erreur dans le chat. L’IA te corrige. Tu valides. Next.
Sauf que la semaine suivante, l’IA refait exactement la même erreur dans un autre fichier. Tu re-copies l’erreur. Elle re-corrige. Tu re-valides. Et à la fin du mois, tu as passé 40 fois sur le même problème sans jamais l’avoir vraiment résolu.
C’est ça, le piège. Tu résous des incidents au lieu de résoudre la classe d’incidents.
Acte 2, le vrai problème, c’est pas l’IA
Quand j’ai commencé à comparer mes runs à ceux de mon pote dev, j’ai vu le truc.
L’IA faisait les mêmes erreurs chez les deux. Sauf que chez lui, elles n’arrivaient qu’une seule fois.
Pas parce que son modèle était plus intelligent. Parce qu’il avait pris l’habitude, à chaque erreur, de se poser une question que moi je sautais systématiquement :
“Comment je fais pour que ça n’arrive plus ?”
Pas “comment je corrige ça maintenant”.
“Comment je fais pour que ça n’arrive plus jamais.”
Et la réponse à cette question, ce n’est jamais un fix dans le code. C’est un changement dans la logique de l’agent.
C’est exactement la même différence qu’entre un junior qui patche un bug et un senior qui patche le système qui produit des bugs.
L’IA, c’est pareil. Elle ne va pas devenir meilleure toute seule. C’est toi qui dois lui apprendre à ne plus faire la même connerie.
Et pour ça, il faut comprendre une distinction fondamentale.
Acte 3, prompt vs skill : la frontière qui change tout

Un prompt, c’est une instruction ponctuelle. Une demande. Un coup unique.
“Génère-moi un screen de login avec ce design.”
Un skill, c’est une instruction durable. Une règle qui s’applique automatiquement à chaque fois qu’on entre dans le contexte concerné.
“À chaque fois que tu touches au login, tu lis d’abord
auth_architecture.md, tu ne mets jamais de logique métier dans le widget, et tu utilises systématiquement le pattern Riverpod défini dansauth_provider.dart.”
Le prompt est jetable. Le skill est capitalisable.
Tu peux écrire 200 prompts par mois et finir l’année exactement au même niveau qu’au début. Tu écris 10 skills bien faits dans la même période, et chaque prompt suivant devient meilleur par défaut, sans que tu aies besoin de répéter quoi que ce soit.
C’est la différence entre enseigner à pêcher et donner un poisson, mais appliquée à un agent qui n’oublie jamais.
Et c’est précisément le levier que la plupart des devs ratent. Ils restent en mode “prompt” indéfiniment. Ils tapent leur instruction custom à chaque fois. Ils corrigent les mêmes erreurs en boucle. Ils ne capitalisent jamais.
Or l’IA est l’outil le plus capitalisable jamais inventé pour un dev solo. À condition de basculer la logique du bon côté.
Acte 4, les 3 réflexes face à l’erreur
C’est là que ça devient concret.
Quand un agent IA produit une erreur, code mal architecturé, fichier au mauvais endroit, pattern qui viole tes conventions, tu as exactement trois réflexes possibles. Et seul le troisième fait grandir ton système.
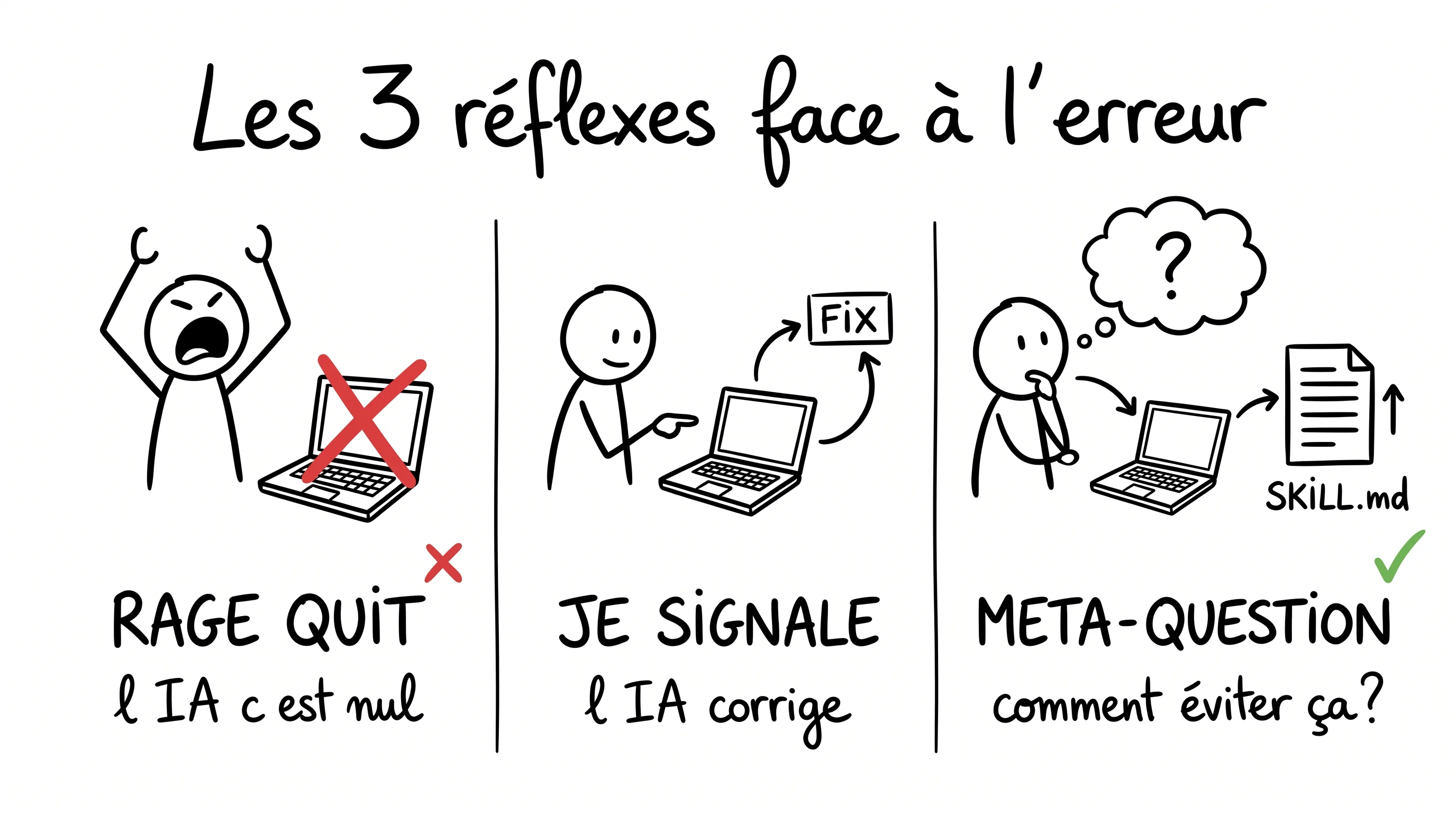
Réflexe 1, le rage quit
“L’IA c’est nul.”
Tu fermes la session. Tu écris le code à la main. Tu te dis que finalement t’es plus rapide tout seul.
C’est le réflexe le plus humain et le plus piégeur. Parce qu’à court terme, tu te sens productif. Tu as livré la feature. Mais tu as perdu deux fois : tu as gaspillé les tokens d’un run raté, et tu as laissé partir une opportunité de rendre l’agent meilleur.
Le rage quit, c’est le réflexe du dev qui finira par dire dans deux ans : “j’ai essayé l’IA, c’était pas pour moi.” Spoiler : c’était pour lui. Il a juste pas tenu.
Réflexe 2, je signale
“L’IA, t’as fait n’importe quoi. Voilà l’erreur. Corrige.”
L’IA corrige. Tu valides. Tu passes à la suite.
C’est mieux que le rage quit. Au moins t’avances. Mais c’est exactement le piège que je décrivais plus haut : la même erreur va revenir la semaine prochaine, parce que rien n’a changé dans la logique de l’agent. Tu as patché un symptôme.
90% des devs qui utilisent une IA restent ici. Pour toujours.
Réflexe 3, la méta-question
“OK, l’IA s’est plantée. Comment je fais pour que ça n’arrive plus ?”
Et là tu remontes d’un niveau. Tu ne corriges plus le code. Tu corriges le système qui a produit ce code.
Concrètement, ça peut donner :
- Ajouter une règle dans le
SKILL.mddu domaine concerné - Créer un fichier d’architecture que l’agent devra lire avant de toucher cette zone
- Remplacer une instruction floue par un exemple précis dans la doc
- Identifier un pattern récurrent et le formaliser dans une convention écrite
- Découvrir que ton skill mélange “contexte de décision” et “contexte d’exécution” et le re-découper
C’est plus lent. La première fois, c’est même nettement plus lent. Au lieu de gagner 5 minutes sur un fix, tu en passes 20 à mettre à jour ton skill.
Mais c’est le seul réflexe qui transforme un coût en un actif.
Acte 5, le compounding du doc
Un skill bien écrit, c’est exactement comme un investissement locatif.
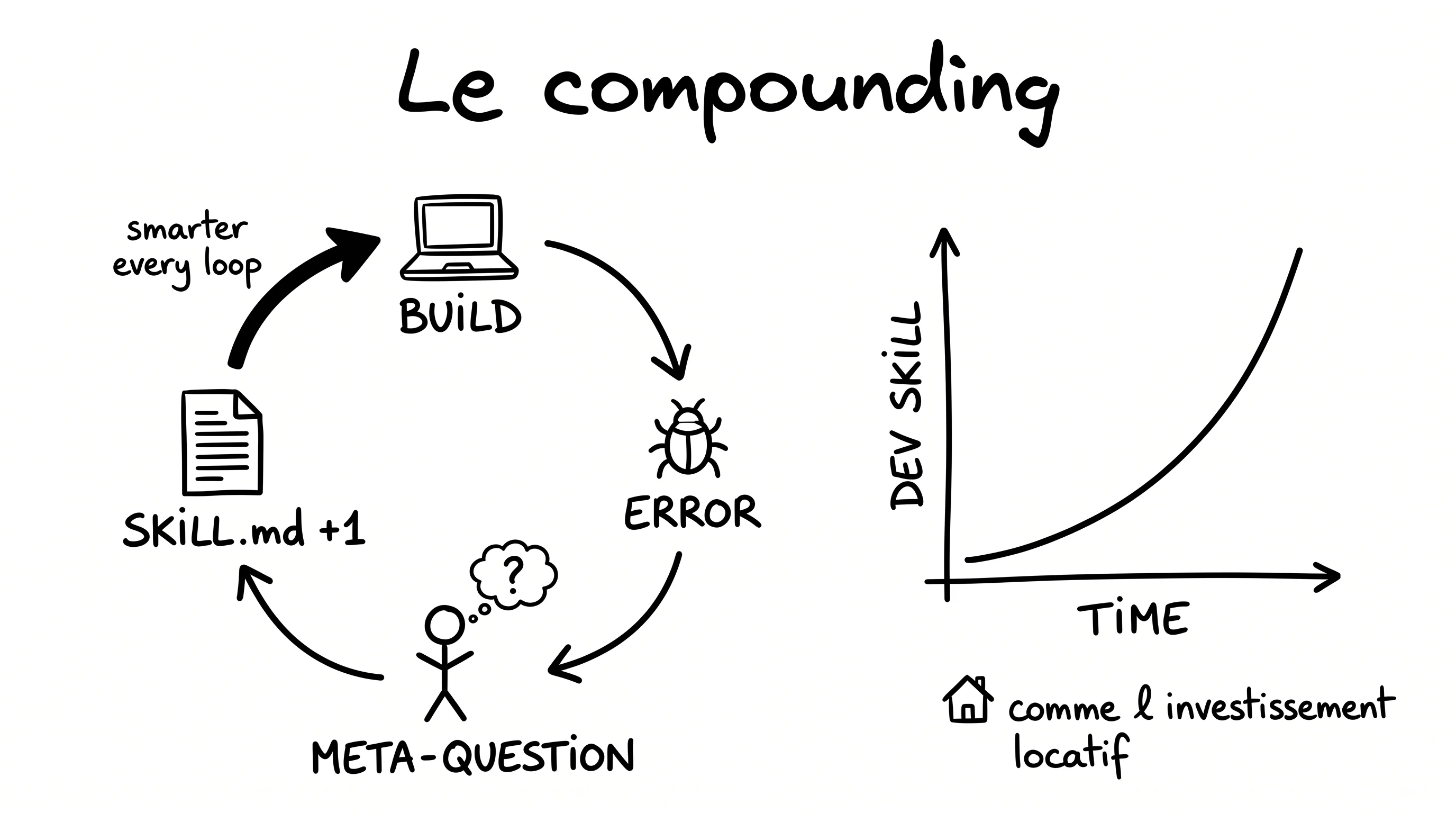
Au début, c’est ingrat. Tu poses 10 lignes de règles dans un fichier markdown, et tu te dis “ça va vraiment changer quelque chose ?”. Tu ne vois rien tout de suite.
Mais à la deuxième erreur évitée, tu sens un truc.
À la dixième, ton skill commence à tourner tout seul.
Au bout de trois mois, l’agent connaît mieux ton codebase que la moitié de tes anciens collègues. Il respecte tes patterns sans que tu aies besoin d’y penser. Il anticipe les pièges qu’il avait l’habitude de tomber dedans.
Et le truc magique, c’est que chaque ligne ajoutée se cumule avec toutes les précédentes. Ton skill grossit, mais surtout il devient plus intelligent. La méta-question d’aujourd’hui prévient les erreurs de demain dans un contexte que tu n’avais même pas anticipé.
C’est ça, le compounding. Ton effort d’aujourd’hui paye plusieurs fois, dans des situations futures que tu n’as pas encore vues.
Et il y a un bonus que personne ne calcule : ton skill survit aux changements de modèle.
J’ai écrit la majorité de mes skills sous Opus. Je suis passé sur GLM 5.1 quand Opus 1M a été retiré. Le système n’a quasiment pas bronché. Pourquoi ? Parce que la logique métier était dans le skill, pas dans le modèle. Le modèle change. Le skill reste.
Un dev qui a 50 skills bien écrits a un asset que personne ne peut lui prendre. Un dev qui a 50 prompts qu’il retape chaque jour à zéro, dans deux ans, il aura encore 0 skill et il sera toujours en train de retaper les mêmes prompts.
L’écart se creuse exponentiellement.
La logique en une phrase
Si tu ne dois retenir qu’un truc de cet article : chaque erreur de l’IA est une chance de la rendre meilleure pour toujours.
Pas pour ce run-là. Pour tous les suivants.
Et la frontière entre “j’utilise l’IA” et “j’ai un agent qui me ressemble” tient dans une seule habitude : prendre 20 minutes au lieu de 5, à chaque fois que ça casse, pour mettre à jour le skill plutôt que le code.
C’est plus lent. C’est plus chiant. C’est aussi la seule chose qui compound.
Conclusion : t’es un investisseur, pas un consommateur
Le bon mental model, ce n’est pas “j’utilise une IA pour coder plus vite”.
C’est “je construis un agent qui me ressemble, et chaque jour il devient un peu plus moi”.
Tu n’es pas un consommateur d’IA. Tu es un investisseur dans ton propre système.
Et comme tout bon investissement : ce qui paye, c’est pas le coup de génie ponctuel. C’est la discipline répétée pendant assez longtemps pour que les intérêts composés fassent leur boulot.
La méta-question, c’est ton ticket d’entrée.
Si tu veux voir comment je structure mes skills concrètement, j’en ai parlé dans Comment j’ai optimisé le contexte de mes agents IA et dans Mon système d’agents IA pour automatiser mon business d’indie dev.
Et toi, tu en es à quel réflexe ? 😄